




Implementation track record
Datachemical LAB has been adopted by a wide range of companies and universities, regardless of product field.
Number of companies using the system: 46
Includes 12 universities and research institutes
Product area of the hiring company
Plastic products
Non-ferrous metals
Electronic Components, Devices, and Circuits
petroleum products
metal products
Space field
Rubber products
Mechanical Products

Features of Datachemical LAB

Can be used in a wide range of industries and fields
Regardless of the material type, it can be used on a single platform for everything from research and development to manufacturing.

High prediction accuracy and extensive analysis functions
"Datachemical LAB" provides the research results of Meiji University's Data Chemical Engineering Laboratory and the latest findings in each field.
It can be implemented in and takes advantage of its rich analysis functions.

Educational support system for acquiring skills
It has a support site and operation guide functions so that even beginners in data science can learn and practice.
We offer a wide range of support to our members.



Areas of use

Chemoinformatics (molecular design)
By quantifying chemical structures and performing machine learning on the relationships between physical properties and activity, we can build models that predict physical properties, activity, and chemical reactions from pre-synthesis chemical structures.We can also estimate chemical structures and their reaction pathways that achieve the target physical properties and activity.

Materials Informatics (Materials Design)
By learning from experimental data, we can build models that predict the physical properties and activity of materials from unknown experimental and manufacturing conditions.We can also estimate the experimental and manufacturing conditions required to obtain target materials from raw material compounds.

Process Informatics (Process Design and Management)
We use process data to design equipment and processes for synthesizing target materials. We also build and operate a system called a soft sensor that uses plant sensor data to estimate factors that are difficult to measure in real time, as well as a model that detects abnormal plant conditions.
Introducing the features
Data Access
You can easily import your existing data, such as table data (CSV format, can mix numbers and strings) and chemical structure data (SMILES format).
Experimental conditions and chemical structure generation
Candidate experimental conditions and chemical structures can be automatically generated in the thousands or even tens of thousands.
Experimental Design
You can statistically narrow down a large number of experimental conditions to effective candidates for initial experiments.
Descriptor Calculation
Chemical structures are converted into numerical data. Both homopolymers and copolymers can be handled.
Data Visualization
Various statistical graphs and dimensionality reduction make it easy to understand the distribution of features and the characteristics between features.
Data Preprocessing
Features can be converted, added, or deleted to adjust them to a form suitable for model building.
Regression analysis
You can consider building a model with high prediction accuracy from various algorithms. In addition, the regression coefficients and importance of each feature are listed, allowing you to check the basis for prediction.
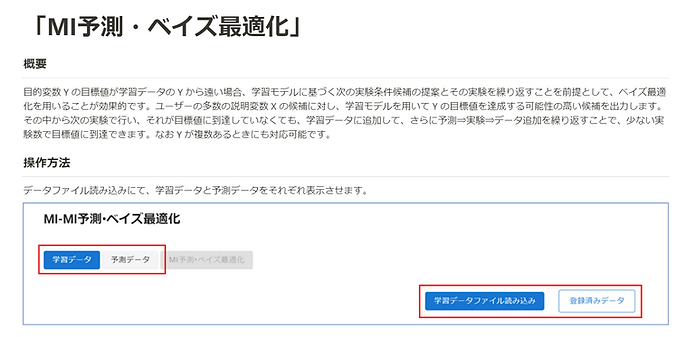
Adaptive Experimental Design
Based on existing experimental data, potential candidates for further experimentation are suggested.
Bayesian Optimization
In adaptive experimental design, this is an effective method when the target value is far from the training data.
Time Series Data Analysis
Models can be built using time-varying data, and predictions can be made at any time based on data measured in real time, enabling soft sensors and anomaly detection to be put into practical use.
Model Optimization
It is easy to automatically optimize parameters and compare the predictive accuracy of various models.
Inverse analysis
After building a predictive model for physical properties and activity, you can determine the conditions for achieving the target values. You can also perform direct reverse analysis, which is not available with other services.
Missing value imputation
When there are missing parts in the training data, the missing values are automatically estimated from the information of the entire feature set.
Classification
Category classification predictions can be made using qualitative data as the objective variable.
mixture calculation
Combining raw material composition data with the physical properties and characteristics data of the raw material itself, new feature quantities are calculated using various calculation methods.
Spectrum
Numerical data from spectra and profiles from analytical instruments can be processed to predict composition and physical properties.
Reagent Database
Data on candidate reagents is extracted from over 490,000 compounds from Fujifilm Wako Pure Chemical Corporation, and after predicting their physical properties and characteristics, you can directly access the product information site for the optimal reagent.
Security
Usage Plan
Business Plans
It can be introduced to manufacturers of various scales. We do not choose the theme, from the development of next-generation materials to the improvement of existing products. We will support you with individual inquiries via email, online interviews, etc.
研究・教育機関向けプラン
We offer special pricing per user to research and educational institutions.
We provide technical support via group chat.
Specialized support site available
How to use each section
It has a wide range of instruction manuals and technical materials tailored to each topic, and you can check the operation flow through videos.
Utilization training
Through practical exercises and model answer videos, you can effectively learn how to use data analysis and machine learning.
